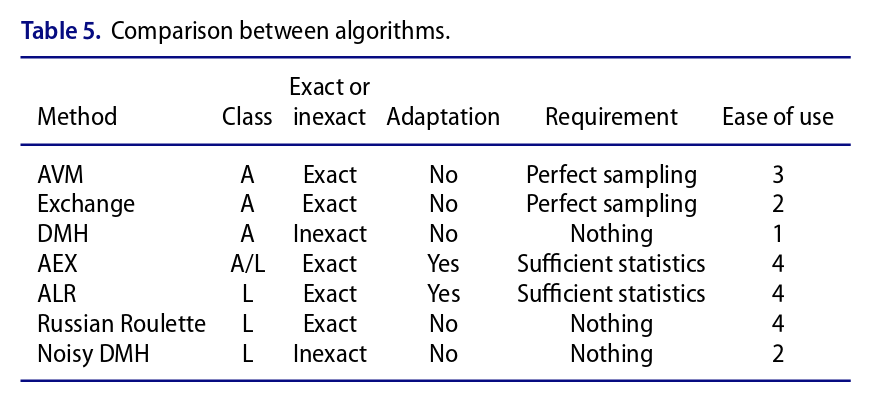
In the latest September issue of JASA I received a few days ago, I spotted a review paper by Jaewoo Park & Murali Haran on intractable normalising constants Z(θ). There have been many proposals for solving this problem as well as several surveys, some conferences and even a book. The current survey focus on MCMC solutions, from auxiliary variable approaches to likelihood approximation algorithms (albeit without ABC entries, even though the 2006 auxiliary variable solutions of Møller et al. et of Murray et al. do simulate pseudo-observations and hence…). This includes the MCMC approximations to auxiliary sampling proposed by Faming Liang and co-authors across several papers. And the paper Yves Atchadé, Nicolas Lartillot and I wrote ten years ago on an adaptive MCMC targeting Z(θ) and using stochastic approximation à la Wang-Landau. Park & Haran stress the relevance of using sufficient statistics in this approach towards fighting computational costs, which makes me wonder if an ABC version could be envisioned. The paper also includes pseudo-marginal techniques like Russian Roulette (once spelled Roullette) and noisy MCMC as proposed in Alquier et al. (2016). These methods are compared on three examples: (1) the Ising model, (2) a social network model, the Florentine business dataset used in our original paper, and a larger one where most methods prove too costly, and (3) an attraction-repulsion point process model. In conclusion, an interesting survey, taking care to spell out the calibration requirements and the theoretical validation, if of course depending on the chosen benchmarks.
In the latest September issue of JASA I received a few days ago, I spotted a review paper by Jaewoo Park & Murali Haran on intractable normalising constants Z(θ). There have been many proposals for solving this problem as well as several surveys, some conferences and even a book. The current survey focus on MCMC solutions, from auxiliary variable approaches to likelihood approximation algorithms (albeit without ABC entries, even though the 2006 auxiliary variable solutions of Møller et al. et of Murray et al. do simulate pseudo-observations and hence…). This includes the MCMC approximations to auxiliary sampling proposed by Faming Liang and co-authors across several papers. And the paper Yves Atchadé, Nicolas Lartillot and I wrote ten years ago on an adaptive MCMC targeting Z(θ) and using stochastic approximation à la Wang-Landau. Park & Haran stress the relevance of using sufficient statistics in this approach towards fighting computational costs, which makes me wonder if an ABC version could be envisioned. The paper also includes pseudo-marginal techniques like Russian Roulette (once spelled Roullette) and noisy MCMC as proposed in Alquier et al. (2016). These methods are compared on three examples: (1) the Ising model, (2) a social network model, the Florentine business dataset used in our original paper, and a larger one where most methods prove too costly, and (3) an attraction-repulsion point process model. In conclusion, an interesting survey, taking care to spell out the calibration requirements and the theoretical validation, if of course depending on the chosen benchmarks.