
At the Sampling, Transport, and Diffusions workshop at the Flatiron Institute, on Day #2, Marilou Gabrié (École Polytechnique) gave the second introductory lecture on merging sampling and normalising flows targeting the target distribution, when driven by a divergence criterion like KL, that only requires the shape of the target density. I first wondered about ergodicity guarantees in simultaneous MCMC and map training due to the adaptation of the flow but the update of the map only depends on the current particle cloud in (8). From an MCMC perspective, it sounds somewhat paradoxical to see the independent sampler making such an unexpected come-back when considering that no insider information is available about the (complex) posterior to drive the [what-you-get-is-what-you-see] construction of the transport map. However, the proposed approach superposed local (random-walk like) and global (transport) proposals in Algorithm 1.
Qiang Liu followed on learning transport maps, with the Interesting notion of causalizing a graph by removing intersections (which are impossible for an ODE, as discussed by Eric Vanden-Eijden’s talk yesterday) through coupling. Which underlies his notion of rectified flows. Possibly connecting with the next lightning talk by Jonathan Weare on spurious modes created by a variational Monte Carlo sampler and the use of stochastic gradient, corrected by (case-dependent?) regularisation.
Then came a whole series of MCMC talks!
Sam Livingstone spoke on Barker’s proposal (an incoming Biometrika paper!) as part of a general class of transforms g of the MH ratio, using jump processes based on a nasty normalising constant related with g (tractable for the original Barker algorithm). I then realised I had missed his StatSci paper on how to speak to statistical physics researchers!
Charles Margossian spoke about using a massive number of short parallel runs (many-short-chain regime) from a recent paper written with Aki, Andrew, and Lionel Riou-Durand (Warwick) among others. Which brings us back to the challenge of producing convergence diagnostics and precisely the Gelman-Rubin R statistic or its recent nR avatar (with its linear limitations and dependence on parameterisation, as opposed to fuller distributional criteria). The core of the approach is in using blocks of GPUs to improve and speed-up the estimation of the between-chain variance. (D for R².) I still wonder at a waste of simulations / computing power resulting from stopping the runs almost immediately after warm-up is over, since reaching the stationary regime or an approximation thereof should be exploited more efficiently. (Starting from a minimal discrepancy sample would also improve efficiency.)
Lu Zhang also talked on the issue of cutting down warmup, presenting a paper co-authored with Bob, Andrew, and Aki, recommending Laplace / variational approximations for reaching faster high-posterior-density regions, using an algorithm called Pathfinder that relies on ELBO checks to counter poor performances of Laplace approximations. In the spirit of the workshop, it could be profitable to further transform / push-forward the outcome by a transport map.
Yuling Yao (of stacking and Pareto smoothing fame!) gave an original and challenging (in a positive sense) talk on the many ways of bridging densities [linked with the remark he shared with me the day before] and their statistical significance. Questioning our usual reliance on arithmetic or geometric mixtures. Ignoring computational issues, selecting a bridging pattern sounds not different from choosing a parameterised family of embedding distributions. This new typology of models can then be endowed with properties that are more or less appealing. (Occurences of the Hyvärinen score and our mixtestin perspective in the talk!)
 Miranda Holmes-Cerfon talked about MCMC on stratification (illustrated by this beautiful picture of nanoparticle random walks). Which means sampling under varying constraints and dimensions with associated densities under the respective Hausdorff measures. This sounds like a perfect setting for reversible jump and in a sense it is, as mentioned in the talks. Except that the moves between manifolds are driven by the proximity to said manifold, helping with a higher acceptance rate, and making the proposals easier to construct since projections (or the reverses) have a physical meaning. (But I could not tell from the talk why the approach was seemingly escaping the symmetry constraint set by Peter Green’s RJMCMC on the reciprocal moves between two given manifolds).
Miranda Holmes-Cerfon talked about MCMC on stratification (illustrated by this beautiful picture of nanoparticle random walks). Which means sampling under varying constraints and dimensions with associated densities under the respective Hausdorff measures. This sounds like a perfect setting for reversible jump and in a sense it is, as mentioned in the talks. Except that the moves between manifolds are driven by the proximity to said manifold, helping with a higher acceptance rate, and making the proposals easier to construct since projections (or the reverses) have a physical meaning. (But I could not tell from the talk why the approach was seemingly escaping the symmetry constraint set by Peter Green’s RJMCMC on the reciprocal moves between two given manifolds).
 On 24 April 2024, Guanyang Wang (Rutgers University, visiting ESSEC) will give a joint All about that Bayes – mostly Monte Carlo seminar on
On 24 April 2024, Guanyang Wang (Rutgers University, visiting ESSEC) will give a joint All about that Bayes – mostly Monte Carlo seminar on
 “We are interested in the question of how we can build differentially-private algorithms
“We are interested in the question of how we can build differentially-private algorithms 
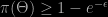
 Next summer, from 19 July till 27 August, there will be a
Next summer, from 19 July till 27 August, there will be a 