
Rob Salomone sent me the following reply on my comments of yesterday about their recently arXived paper.
Our main goal in the paper was to show that Nested Sampling (when interpreted a certain way) is really just a member of a larger class of SMC algorithms, and exploring the consequences of that. We should point out that the section regarding calibration applies generally to SMC samplers, and hope that people give those techniques a try regardless of their chosen SMC approach.
Regarding your question about “whether or not it makes more sense to get completely SMC and forego any nested sampling flavour!”, this is an interesting point. After all, if Nested Sampling is just a special form of SMC, why not just use more standard SMC approaches? It seems that the Nested Sampling’s main advantage is its ability to cope with problems that have “phase transition’’ like behaviour, and thus is robust to a wider range of difficult problems than annealing approaches. Nevertheless, we hope this way of looking at NS (and showing that there may be variations of SMC with certain advantages) leads to improved NS and SMC methods down the line.
Regarding your post, I should clarify a point regarding unbiasedness. The largest likelihood bound is actually set to infinity. Thus, for the fixed version of NS—SMC, one has an unbiased estimator of the “final” band. Choosing a final band prematurely will of course result in very high variance. However, the estimator is unbiased. For example, consider NS—SMC with only one strata. Then, the method reduces to simply using the prior as an importance sampling distribution for the posterior (unbiased, but often high variance).
Comments related to two specific parts of your post are below (your comments in italicised bold):
“Which never occurred as the number one difficulty there, as the simplest implementation runs a Markov chain from the last removed entry, independently from the remaining entries. Even stationarity is not an issue since I believe that the first occurrence within the level set is distributed from the constrained prior.”
This is an interesting point that we had not considered! In practice, and in many papers that apply Nested Sampling with MCMC, the common approach is to start the MCMC at one of the randomly selected “live points”, so the discussion related to independence was in regard to these common implementations.
Regarding starting the chain from outside of the level set. This is likely not done in practice as it introduces an additional difficulty of needing to propose a sample inside the required region (Metropolis–Hastings will have non—zero probability of returning a sample that is still outside the constrained region for any fixed number of iterations). Forcing the continuation of MCMC until a valid point is proposed I believe will be a subtle violation of detailed balance. Of course, the bias of such a modification may be small in practice, but it is an additional awkwardness introduced by the requirement of sample independence!
“And then, in a twist that is not clearly explained in the paper, the focus moves to an improved nested sampler that moves one likelihood value at a time, with a particle step replacing a single particle. (Things get complicated when several particles may take the very same likelihood value, but randomisation helps.) At this stage the algorithm is quite similar to the original nested sampler. Except for the unbiased estimation of the constants, the final constant, and the replacement of exponential weights exp(-t/N) by powers of (N-1/N)”
Thanks for pointing out that this isn’t clear, we will try to do better in the next revision! The goal of this part of the paper wasn’t necessarily to propose a new version of nested sampling. Our focus here was to demonstrate that NS–SMC is not simply the Nested Sampling idea with an SMC twist, but that the original NS algorithm with MCMC (and restarting the MCMC sampling at one of the “live points’” as people do in practice) actually is a special case of SMC (with the weights replaced with a suboptimal choice).
The most curious thing is that, as you note, the estimates of remaining prior mass in the SMC context come out as powers of (N-1)/N and not exp(-t/N). In the paper by Walter (2017), he shows that the former choice is actually superior in terms of bias and variance. It was a nice touch that the superior choice of weights came out naturally in the SMC interpretation!
That said, as the fixed version of NS-SMC is the one with the unbiasedness and consistency properties, this was the version we used in the main statistical examples.
 With Achille Thin and a few other coauthors [and friends], we just arXived a paper on a new form of importance sampling, motivated by a recent paper of Rotskoff and Vanden-Eijnden (2019) on non-equilibrium importance sampling. The central ideas of this earlier paper are the introduction of conformal Hamiltonian dynamics, where a dissipative term is added to the ODE found in HMC, namely
With Achille Thin and a few other coauthors [and friends], we just arXived a paper on a new form of importance sampling, motivated by a recent paper of Rotskoff and Vanden-Eijnden (2019) on non-equilibrium importance sampling. The central ideas of this earlier paper are the introduction of conformal Hamiltonian dynamics, where a dissipative term is added to the ODE found in HMC, namely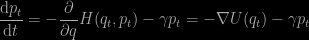
 The resulting InFiNE algorithm is an MCMC particular algorithm which can be represented as a partially collapsed Gibbs sampler when using the right auxiliary variables. As in Andrieu, Doucet and Hollenstein (2010) and their ISIR algorithm. The algorithm can be used for estimating normalising constants, comparing favourably with AIS, sampling from complex targets, and optimising variational autoencoders and their ELBO.
The resulting InFiNE algorithm is an MCMC particular algorithm which can be represented as a partially collapsed Gibbs sampler when using the right auxiliary variables. As in Andrieu, Doucet and Hollenstein (2010) and their ISIR algorithm. The algorithm can be used for estimating normalising constants, comparing favourably with AIS, sampling from complex targets, and optimising variational autoencoders and their ELBO.



