 Read Kawabata’s Sound of the Mountain, which I also found in a Montréal bookstore. At first, I thought it was connected to the masterpiece House of Sleeping Beauties, which I read eons ago, as dreams are also central to that (mostly) domestic and familial story, but this was quite another, more personal, and poignant reflection on aging and the irreversibility of time. As well as an unsuspected window into immediate post-war Japan. (With the realisation that abortion was completely acceptable then.) Also spotted Greg Bear’s Darwin’s Children in my Canadian cabin, which I started and finished later with a Kindle version. As I was unaware of a sequel to the fabulous Darwin’s Radio. Overall, I was almost as enthusiastic about it as I was with the first book, but obviously suffering from an academic bias as the author engages into speculative population genetics, which may prove too much for non-academics… (Imho, the end is wasted, though.) And (binge) read January Fifteenth on the flight back (leaving too early to sleep!), which is a short novel whose only speculative aspect is the move (by the US Government) to a universal basic income (UBI) for all individuals, and the consequences on several women’s live. This was indeed a very quick read, presumably due to the high proportion of dialogues, with (variably) interesting characters that avoid a direct take on the concept, but somewhat charicaturesque nonetheless. The implementation of the scheme is rather vaguely described: January 15 is the calendar day people pick their yearly UBI and they have to do it in person to avoid been coerced or scammed into transferring it to someone else. As someone rather interested in this societal propsal, this book did not modify my views on the concept or on its practical aspects, but shed light on some potential consequences of (one version of) it.
Read Kawabata’s Sound of the Mountain, which I also found in a Montréal bookstore. At first, I thought it was connected to the masterpiece House of Sleeping Beauties, which I read eons ago, as dreams are also central to that (mostly) domestic and familial story, but this was quite another, more personal, and poignant reflection on aging and the irreversibility of time. As well as an unsuspected window into immediate post-war Japan. (With the realisation that abortion was completely acceptable then.) Also spotted Greg Bear’s Darwin’s Children in my Canadian cabin, which I started and finished later with a Kindle version. As I was unaware of a sequel to the fabulous Darwin’s Radio. Overall, I was almost as enthusiastic about it as I was with the first book, but obviously suffering from an academic bias as the author engages into speculative population genetics, which may prove too much for non-academics… (Imho, the end is wasted, though.) And (binge) read January Fifteenth on the flight back (leaving too early to sleep!), which is a short novel whose only speculative aspect is the move (by the US Government) to a universal basic income (UBI) for all individuals, and the consequences on several women’s live. This was indeed a very quick read, presumably due to the high proportion of dialogues, with (variably) interesting characters that avoid a direct take on the concept, but somewhat charicaturesque nonetheless. The implementation of the scheme is rather vaguely described: January 15 is the calendar day people pick their yearly UBI and they have to do it in person to avoid been coerced or scammed into transferring it to someone else. As someone rather interested in this societal propsal, this book did not modify my views on the concept or on its practical aspects, but shed light on some potential consequences of (one version of) it.
 Had a great time in a Lac-Saint-Jean cabin, with direct access to the lake. Albeit requiring the emergency purchase of a neoprene swimming suit, as the temperature of the lake was rather low for extended swimming without it. But otherwise, having a swell time every morning, often running and swimming and biking. Before hiking. (The last week, farther south, next to a much smaller lake I could easily cross, did not require the suit!) Also appreciated very much the almost flat véliroute des Bleuets (blueberries) that run all around the lake (even though some sections are alas shared with cars). Has for instance an uninterrupted 15K connection to the nearest (genuine) bakery+cheese-mongery!
Had a great time in a Lac-Saint-Jean cabin, with direct access to the lake. Albeit requiring the emergency purchase of a neoprene swimming suit, as the temperature of the lake was rather low for extended swimming without it. But otherwise, having a swell time every morning, often running and swimming and biking. Before hiking. (The last week, farther south, next to a much smaller lake I could easily cross, did not require the suit!) Also appreciated very much the almost flat véliroute des Bleuets (blueberries) that run all around the lake (even though some sections are alas shared with cars). Has for instance an uninterrupted 15K connection to the nearest (genuine) bakery+cheese-mongery!  Made an attempt at kouign amann, but using the wrong type of both flour and cassonade, plus an unknown oven and the poor substitute of baking soda for yeast predictably failed the experiment, even though the outcome was eatable (and eaten within a few days).
Made an attempt at kouign amann, but using the wrong type of both flour and cassonade, plus an unknown oven and the poor substitute of baking soda for yeast predictably failed the experiment, even though the outcome was eatable (and eaten within a few days).
 As usual (!), did not spot much wildlife, beyond groundhogs, pikas, squirrels, beavers and muskrats in our rental’s lake, moose tracks here and there, and a few Virginia deer in the Mauricie National Park. (Which made me realise that national and regional [Québec] parks co-existed in the area.) Had a few traditional hikes, reconnecting with Deet to keep mosquitoes and black flies at bay.
As usual (!), did not spot much wildlife, beyond groundhogs, pikas, squirrels, beavers and muskrats in our rental’s lake, moose tracks here and there, and a few Virginia deer in the Mauricie National Park. (Which made me realise that national and regional [Québec] parks co-existed in the area.) Had a few traditional hikes, reconnecting with Deet to keep mosquitoes and black flies at bay.
Watched nothing at all! In part due to my wife often borrowing my laptop for its Netflix connection, in part due to my early sleep caused by earlier rise, as light comes before 5am in this part of Québec we were staying, which made an ideal opportunity for very early run, swim, and… Biometrika editing!
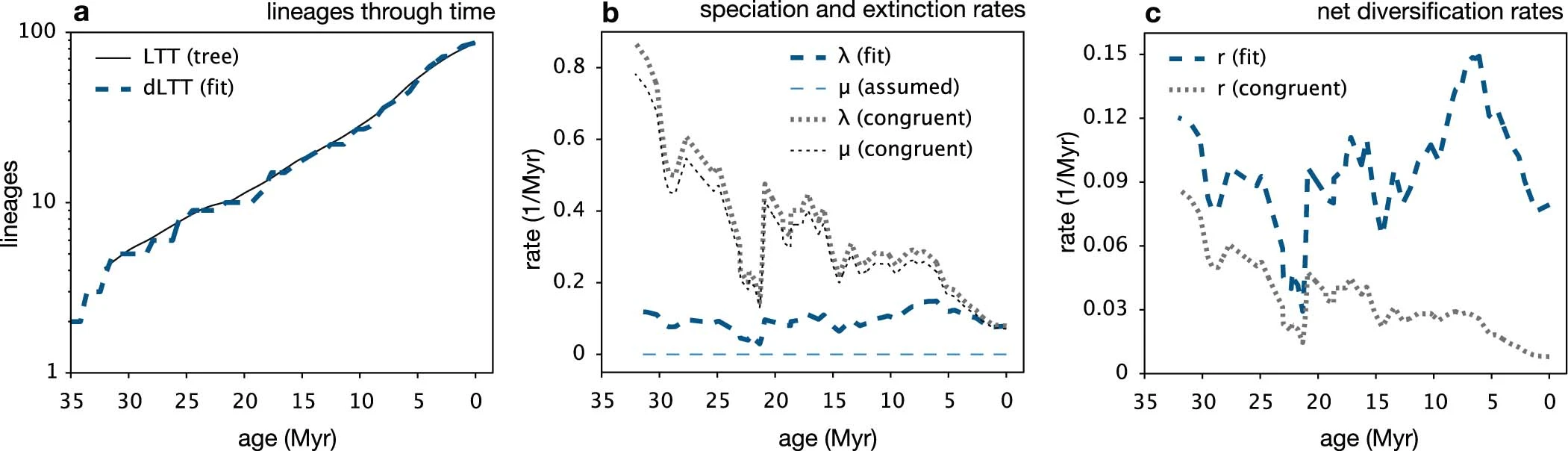
 $
$

 ,
,

