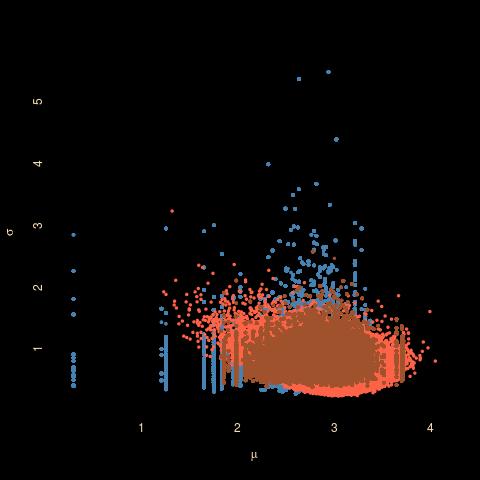
At the MHC 2021 conference today (to which I biked to attend for real!, first time since BayesComp!) I listened to Christophe Biernacki exposing the dangers of EM applied to mixtures in the presence of missing data, namely that the algorithm has a rising probability to reach a degenerate solution, namely a single observation component. Rising in the proportion of missing data. This is not hugely surprising as there is a real (global) mode at this solution. If one observation components are prohibited, they should not be accepted in the EM update. Just as in Bayesian analyses with improper priors, the likelihood should bar single or double observations components… Which of course makes EM harder to implement. Or not?! MCEM, SEM and Gibbs are obviously straightforward to modify in this case.
At the MHC 2021 conference today (to which I biked to attend for real!, first time since BayesComp!) I listened to Christophe Biernacki exposing the dangers of EM applied to mixtures in the presence of missing data, namely that the algorithm has a rising probability to reach a degenerate solution, namely a single observation component. Rising in the proportion of missing data. This is not hugely surprising as there is a real (global) mode at this solution. If one observation components are prohibited, they should not be accepted in the EM update. Just as in Bayesian analyses with improper priors, the likelihood should bar single or double observations components… Which of course makes EM harder to implement. Or not?! MCEM, SEM and Gibbs are obviously straightforward to modify in this case.
 Judith Rousseau also gave a fascinating talk on the properties of non-parametric mixtures, from a surprisingly light set of conditions for identifiability to posterior consistency . With an interesting use of several priors simultaneously that is a particular case of the cut models. Namely a correct joint distribution that cannot be a posterior, although this does not impact simulation issues. And a nice trick turning a hidden Markov chain into a fully finite hidden Markov chain as it is sufficient to recover a Bernstein von Mises asymptotic. If inefficient. Sylvain LeCorff presented a pseudo-marginal sequential sampler for smoothing, when the transition densities are replaced by unbiased estimators. With connection with approximate Bayesian computation smoothing. This proves harder than I first imagined because of the backward-sampling operations…
Judith Rousseau also gave a fascinating talk on the properties of non-parametric mixtures, from a surprisingly light set of conditions for identifiability to posterior consistency . With an interesting use of several priors simultaneously that is a particular case of the cut models. Namely a correct joint distribution that cannot be a posterior, although this does not impact simulation issues. And a nice trick turning a hidden Markov chain into a fully finite hidden Markov chain as it is sufficient to recover a Bernstein von Mises asymptotic. If inefficient. Sylvain LeCorff presented a pseudo-marginal sequential sampler for smoothing, when the transition densities are replaced by unbiased estimators. With connection with approximate Bayesian computation smoothing. This proves harder than I first imagined because of the backward-sampling operations…