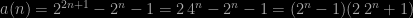Following a question on X validated about the reasons for coding rexp() following Ahrens & Dieter (1972) version, I re-read Luc Devroye’s explanations. Which boils down to an optimised implementation of von Neumann’s Exponential generator. The central result is that, for any μ>0, M a Geometric variate with failure probability exp(-μ) and Z a positive Poisson variate with parameter μ

is distributed as an Exp(1) random variate. Meaning that for every scale μ, the integer part and the fractional part of an Exponential variate are independent, the former a Geometric. A refinement of the above consists in choosing
exp(-μ) =½
as the generation of M then consists in counting the number of 0’s before the first 1 in the binary expansion of U∼U(0,1). Actually the loop used in Ahrens & Dieter (1972) seems to be much less efficient than counting these 0’s
> benchmark("a"={u=runif(1)
while(u<.5){
u=2*u
F=F+log(2)}},
"b"={v=as.integer(rev(intToBits(2^31*runif(1))))
sum(cumprod(!v))},
"c"={sum(cumprod(sample(c(0,1),32,rep=T)))},
"g"={rgeom(1,prob=.5)},replications=1e4)
test elapsed relative user.self
1 a 32.92 557.966 32.885
2 b 0.123 2.085 0.122
3 c 0.113 1.915 0.106
4 g 0.059 1.000 0.058
Obviously, trying to code the change directly in R resulted in much worse performances than the resident rexp(), coded in C.